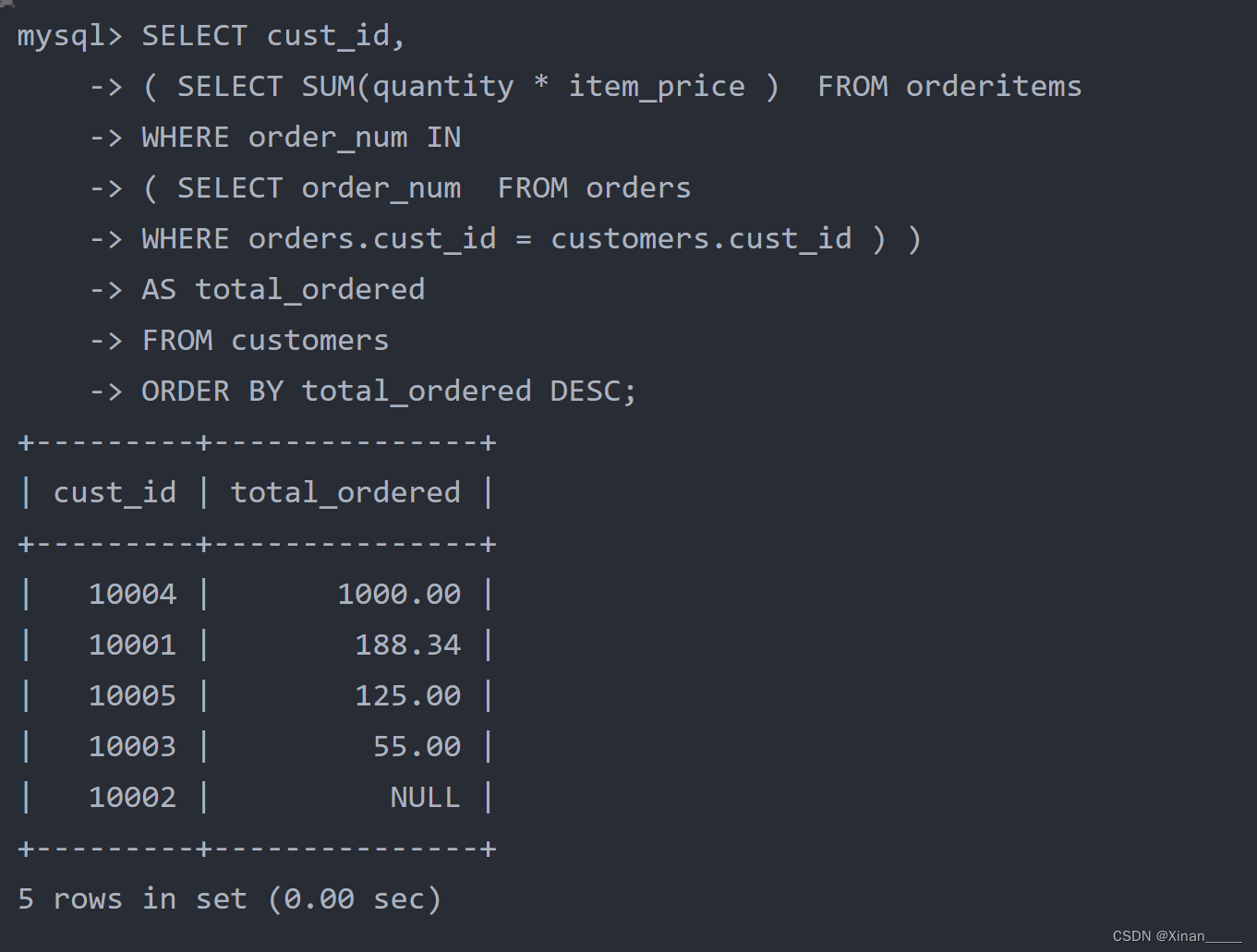
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]] 输出:true 解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]] 输出:false 解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
这道题说人话就算判断这个有向图有没有环路。
我们知道拓扑排序可以用来判断是否有环路,不过仅仅是判断环路也可以直接用dfs,不需要完全写出拓扑排序,毕竟拓扑排序相比dfs还是更复杂一些。
下面给出上述两种思路的代码
1.拓扑排序判断
我的拓扑排序的代码思路是参考王道书介绍的思路
class Solution {
public:
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> graph(numCourses, vector<int>(numCourses));//邻接矩阵
vector<int> indegree(numCourses, 0);//每个节点的入度
for (int i = 0; i < prerequisites.size(); i++) {
graph[prerequisites[i][1]][prerequisites[i][0]] = 1;//构造邻接矩阵
indegree[prerequisites[i][0]]++;//修改该点的入度
}
stack<int> stk;//用栈或队列都可以
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0)//入度为0的点入栈
stk.push(i);
}
int cnt = 0;//记录节点的数量
while (!stk.empty()) {
int i = stk.top();
stk.pop();
//如果是正常的拓扑排序,这里就可以输出节点了,本题只要求判断环路
cnt++;//出栈的节点入度都为0,cnt++
for (int j = 0; j < numCourses; j++) {//遍历当前节点的临边
if (graph[i][j] != 0) {
graph[i][j] = 0;//删除这条有向边
indegree[j]--;//相邻边的入度减1
if (indegree[j] == 0)//如果临边入度为0,入栈
stk.push(j);
}
}
}
return cnt == numCourses;//最终的判断条件,cnt不为n,则有环路
//因为有环路的情况下环路上的节点的入度不可能为0,就不会入栈,所以最后cnt的值不为n
}
};下面用一张图作为示例:
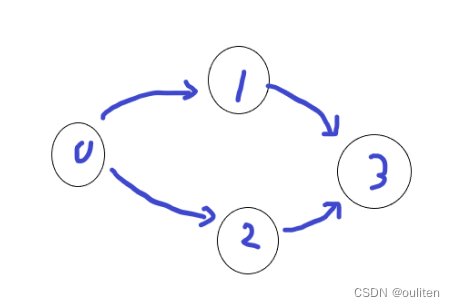
一开始只有0的度为0,所以0入栈,出栈时会执行这一段代码
for (int j = 0; j < numCourses; j++) {//遍历当前节点的临边
if (graph[i][j] != 0) {
graph[i][j] = 0;//删除这条有向边
indegree[j]--;//相邻边的入度减1
if (indegree[j] == 0)//如果临边入度为0,入栈
stk.push(j);
}
}那么就把从0开始的弧都删掉,并把弧所指向的节点的入度减1
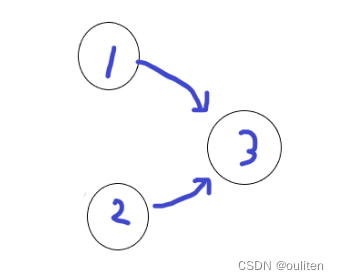
这时候1和2的入度就为0了,入栈。然后2先出栈,把2->3这段弧也删掉

但是此时3的入度不为0,也就先不会入栈。然后1出栈,把1->3这段弧删掉

这时候3的入度也为0,3入栈。3再出栈,3出栈反正啥也不会做。
最终,4个节点全部入了栈,因此cnt==n成立,该图是无环有向图。
如果是有环图,可以自己试一下,最后图里会剩下环,因为环上所有节点的入度都不为0,因此不会入栈。
2.dfs
class Solution {
public:
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
graph=vector<vector<int>>(numCourses, vector<int>(numCourses));//邻接矩阵
vis = vector<int>(numCourses, 0);//visit数组
valid = true;//标记是否存在环路
vector<int> indegree(numCourses, 0);
for (int i = 0; i < prerequisites.size(); i++) {
graph[prerequisites[i][1]][prerequisites[i][0]] = 1;
}
//以上和拓扑排序都是一样的步骤
for (int i = 0; i < numCourses; i++) {
dfs(i);
}
return valid;
}
private:
void dfs(int u) {
if (!valid) return;//如果存在环路直接返回
if (vis[u] == 1) { valid = false; return; }//如果当前节点正在遍历,则表明存在环路
if (vis[u] == 2) return;//如果当前节点已经遍历完成,直接返回
vis[u] = 1;//vis置为1,表示当前节点正在dfs中
for (int v = 0; v < vis.size(); v++) {//遍历当前节点的临边
if (graph[u][v] != 0) {
dfs(v);
if (!valid) return;//有环直接退出
}
}
vis[u] = 2;//置为2,表示当前节点已经走过了
}
bool valid;
vector<int> vis;
vector<vector<int>> graph;
};关键点在于vis数组的值有1和2的区分
画图解释,设1代表蓝色,2代表红色

从0出发,进行一次dfs,假设路径是0-1-3-4,那么最后1,3,4会变成红色,0还是蓝色

之后dfs会走2这条路

走到2后,会再次调用dfs(3),但是因为
if (vis[u] == 2) return;//如果当前节点已经遍历完成,直接返回所以valid还是true;
如果是有环路的情况,从0出发进行一次dfs
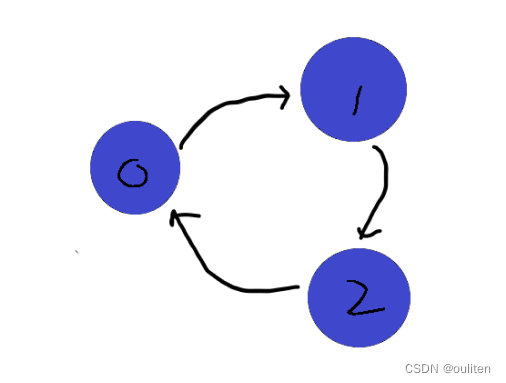
走到2后会再次调用dfs(0),而
if (vis[u] == 1) { valid = false; return; }//如果当前节点正在遍历,则表明存在环路所以有环路。