概述
结果值的处理相当于参数的处理会复杂一些,负责结果值转换的类是 ResultSetHandler
java">public interface ResultSetHandler {
/**
* 处理数据集并返回
* @param stmt
* @param <E>
* @return
* @throws SQLException
*/
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
<E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
这里将存储过程、游标相关的忽略,我们只看普通的处理就行。
相当于就一个方法handleResultSets,处理ResultSet转换结果值。
ResultSetHandler只有一个实现类,即DefaultResultSetHandler。
但在解析结果值的时候还依赖一些其他的类。
ResultSetWrapper:ResultSet包装器,丰富ResultSet方法,包含了ResultSet相关元数据
ResultContext:结果值上下文,存储值结果值、总数等。
ResultHandler:结果处理器。做处理完的类型转换的结果,进行后置处理。
ResultSetWrapper
java">public class ResultSetWrapper {
/**
* 数据集
*/
private final ResultSet resultSet;
private final TypeHandlerRegistry typeHandlerRegistry;
/**
* 字段名集合
*/
private final List<String> columnNames = new ArrayList<>();
/**
* 字段对应的javaType类型名
*/
private final List<String> classNames = new ArrayList<>();
/**
* jdbcType
*/
private final List<JdbcType> jdbcTypes = new ArrayList<>();
// 类型处理器
private final Map<String, Map<Class<?>, TypeHandler<?>>> typeHandlerMap = new HashMap<>();
/**
* 针对当前ResultSet中,resultMap中映射的字段名
* key: resultMapId
* value:resultMap映射字段
*/
private final Map<String, List<String>> mappedColumnNamesMap = new HashMap<>();
/**
* 针对当前ResultSet中,resultMap中未映射的字段名
* key: resultMapId
* value:resultMap未映射字段
*/
private final Map<String, List<String>> unMappedColumnNamesMap = new HashMap<>();
public ResultSetWrapper(ResultSet rs, Configuration configuration) throws SQLException {
super();
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();
this.resultSet = rs;
// 从ResultSet中获取元数据
final ResultSetMetaData metaData = rs.getMetaData();
// 总列数
final int columnCount = metaData.getColumnCount();
for (int i = 1; i <= columnCount; i++) {
// columnLabel代表as的值,columnName代表原名
// 默认取columnLabel的值
columnNames.add(configuration.isUseColumnLabel() ? metaData.getColumnLabel(i) : metaData.getColumnName(i));
// 每个字段对应的jdbc类型
jdbcTypes.add(JdbcType.forCode(metaData.getColumnType(i)));
// 每个字段对应的java类型
classNames.add(metaData.getColumnClassName(i));
}
}
}
ResultSetWrapper包装了ResultSet,通过ResultSetMetaData(JDBC)获取列信息。结合ResultMap进行列相关方法的提供。
看下ResultSetWrapper提供的所有方法:
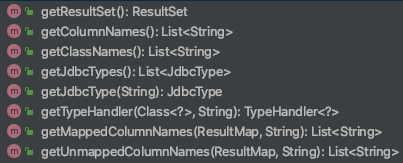
基本是针对自身属性提供的get方法,了解了各个属性的意义之后,方法的作用也就比较清楚了。
ResultContext
java">public interface ResultContext<T> {
T getResultObject();
int getResultCount();
boolean isStopped();
void stop();
}
结果的载体,实现类 DefaultResultContext
DefaultResultContext
java">public class DefaultResultContext<T> implements ResultContext<T> {
/**
* 结果值
*/
private T resultObject;
/**
* 累计的结果数量
*/
private int resultCount;
/**
* 是否停止
*/
private boolean stopped;
public DefaultResultContext() {
resultObject = null;
resultCount = 0;
stopped = false;
}
@Override
public T getResultObject() {
return resultObject;
}
@Override
public int getResultCount() {
return resultCount;
}
@Override
public boolean isStopped() {
return stopped;
}
public void nextResultObject(T resultObject) {
resultCount++;
this.resultObject = resultObject;
}
@Override
public void stop() {
this.stopped = true;
}
}
so easy。
ResultHandler
java">public interface ResultHandler<T> {
void handleResult(ResultContext<? extends T> resultContext);
}
传入ResultContext,进行结果后置处理
DefaultResultHandler
java">public class DefaultResultHandler implements ResultHandler<Object> {
private final List<Object> list;
public DefaultResultHandler() {
list = new ArrayList<>();
}
@SuppressWarnings("unchecked")
public DefaultResultHandler(ObjectFactory objectFactory) {
list = objectFactory.create(List.class);
}
@Override
public void handleResult(ResultContext<?> context) {
// 就仅当结果存储
list.add(context.getResultObject());
}
public List<Object> getResultList() {
return list;
}
}
主要就是将结果存储到list中。
DefaultMapResultHandler
主要是MapKey注解的实现。这里科普下@MapKey的作用,就是将mapper的返回值转换成Map类型。@MapKey 就是指定返回map的key。
java">public class DefaultMapResultHandler<K, V> implements ResultHandler<V> {
/**
* 对应的map结果
* key:mapKey对应的值
* value:原结果
*/
private final Map<K, V> mappedResults;
private final String mapKey;
private final ObjectFactory objectFactory;
private final ObjectWrapperFactory objectWrapperFactory;
private final ReflectorFactory reflectorFactory;
@SuppressWarnings("unchecked")
public DefaultMapResultHandler(String mapKey, ObjectFactory objectFactory, ObjectWrapperFactory objectWrapperFactory, ReflectorFactory reflectorFactory) {
this.objectFactory = objectFactory;
this.objectWrapperFactory = objectWrapperFactory;
this.reflectorFactory = reflectorFactory;
this.mappedResults = objectFactory.create(Map.class);
this.mapKey = mapKey;
}
@Override
public void handleResult(ResultContext<? extends V> context) {
final V value = context.getResultObject();
// 创建MetaObject实例
final MetaObject mo = MetaObject.forObject(value, objectFactory, objectWrapperFactory, reflectorFactory);
// 取出key值
final K key = (K) mo.getValue(mapKey);
// 构造map值
mappedResults.put(key, value);
}
public Map<K, V> getMappedResults() {
return mappedResults;
}
ResultSetHandler
主人公出现,铺垫了相关类之后,开始分析ResultSetHandler。
java">public interface ResultSetHandler {
/**
* 处理数据集并返回
* @param stmt
* @param <E>
* @return
* @throws SQLException
*/
<E> List<E> handleResultSets(Statement stmt) throws SQLException;
// 游标忽略
<E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException;
// 存储过程忽略
void handleOutputParameters(CallableStatement cs) throws SQLException;
}
ResultSetHandler就只有一个实现类 DefaultResultSetHandler。
DefaultResultSetHandler
先看下DefaultResultSetHandler的属性和构造方法
java">public class DefaultResultSetHandler implements ResultSetHandler {
private static final Object DEFERRED = new Object();
// 执行器
private final Executor executor;
// 配置
private final Configuration configuration;
// 映射Statement
private final MappedStatement mappedStatement;
// 分页参数
private final RowBounds rowBounds;
// 参数处理器
private final ParameterHandler parameterHandler;
// 结果处理器
private final ResultHandler<?> resultHandler;
// 动态sql载体
private final BoundSql boundSql;
// 类型处理器容器
private final TypeHandlerRegistry typeHandlerRegistry;
// 对象工厂
private final ObjectFactory objectFactory;
// 反射器工厂
private final ReflectorFactory reflectorFactory;
// 嵌套结果
private final Map<CacheKey, Object> nestedResultObjects = new HashMap<>();
// 未知,忽略
private final Map<String, Object> ancestorObjects = new HashMap<>();
// 上一条行值
private Object previousRowValue;
// multiple resultsets
private final Map<String, ResultMapping> nextResultMaps = new HashMap<>();
private final Map<CacheKey, List<PendingRelation>> pendingRelations = new HashMap<>();
// Cached Automappings
private final Map<String, List<UnMappedColumnAutoMapping>> autoMappingsCache = new HashMap<>();
// temporary marking flag that indicate using constructor mapping (use field to reduce memory usage)
private boolean useConstructorMappings;
// 构造函数
public DefaultResultSetHandler(Executor executor, MappedStatement mappedStatement, ParameterHandler parameterHandler, ResultHandler<?> resultHandler, BoundSql boundSql,
RowBounds rowBounds) {
this.executor = executor;
this.configuration = mappedStatement.getConfiguration();
this.mappedStatement = mappedStatement;
this.rowBounds = rowBounds;
this.parameterHandler = parameterHandler;
this.boundSql = boundSql;
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();
this.objectFactory = configuration.getObjectFactory();
this.reflectorFactory = configuration.getReflectorFactory();
this.resultHandler = resultHandler;
}
这里实例化的入口是BaseStatementHandler的构造函数
java">protected BaseStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
...
this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql);
this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql);
}
虽然参数比较多,但还算清楚。
DefaultResultSetHandler也就仅需要实现 handleResultSets这么一个方法。
我觉得分析源码比较好的方式是,先设想它的实现原理,然后再通过代码求证,这样提前有了自己的思考,在看源码时就可以挑重点的看,不至于被庞大的分支绕晕了。
那我们这里先想想结果值的处理会是怎么样的过程,
给到你一个ResultSet,怎么转换成目标类型?
- 遍历ResultSet行(一行一行处理,保存到List中一起返回)。
- 创建目标类型实例(构造函数反射)。
- 遍历ResultSet中的列,根据列的jdbc类型找到TypeHandler
- 通过TypeHandler和列的值转换成javaType。
- 将转换后的列值反射设置值到目标的属性中。
构思下大概流程,接着通过代码佐证。
handleResultSets
java">@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
/*
* 获取第一个结果集,包装了一下
* 基本上只有一个结果集,存储过程才可能有多个
*/
ResultSetWrapper rsw = getFirstResultSet(stmt);
/*
* 获取结果映射map,这里虽然是list,但是我们日常几乎都是单ResultMap
*/
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
/*
* 遍历resultMaps,从0开始,也就是按照resultMap中定义的字段顺序来处理
*
*/
while (rsw != null && resultMapCount > resultSetCount) {
//每个数据集一个ResultMap
ResultMap resultMap = resultMaps.get(resultSetCount);
// 真正开始处理转换
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个数据集
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
//索引累加
resultSetCount++;
}
// 存储过程相关代码忽略
...
/*
* 如果是单数据集,就将其展开返回
* multipleResults的结构是List<List<Object>>
* 这种结构是为了支持多数据集,存储过程可能返回多个数据集。
*/
return collapseSingleResultList(multipleResults);
}
这里mybatis对存储过程和普通sql进行了通用的处理,体现在存储过程有多ResultSet、ResultMap,我们在分析的时候只关注与List的第一个元素即可。
handleResultSet
处理单个ResultSet。
java">private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
try {
// 普通sql无父Mapping
if (parentMapping != null) {
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
// 一般使用时 不会主动指定ResultHandler
if (resultHandler == null) {
/*
* 处理数据,并将结果存储在ResultHandler上
* 最终转嫁到multipleResults上,向上透出
*/
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
// 处理行值
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
// 将处理好的结果设置到multipleResults
multipleResults.add(defaultResultHandler.getResultList());
} else {
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
closeResultSet(rsw.getResultSet());
}
}
如果mapper方法中没有直接执行ResultHandler,那么创建默认的ResultHandler做结果收集。
handleRowValues
java">public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
//判断是否有嵌套ResultMap
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
// 普通ResultMap解析
else {
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
进入到简单ResultMap解析
handleRowValuesForSimpleResultMap
java">private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
ResultSet resultSet = rsw.getResultSet();
/*
* 根据分页参数的offset 跳过指定的行,ROwBounds是伪分页
*/
skipRows(resultSet, rowBounds);
/*
* 遍历每一行数据
*/
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
//获取鉴别器ResultMap? 鉴别器使用很少,忽略
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
//获取一行的记录
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
//将结果(rowValue)存储在resultHandler上
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
这里 getRowValue 返回解析好的单行值,已经将单行转换成javaBean的实例了。
storeObject方法针对返回的行值进行ResultHandler处理。(默认ResultHandler就是存储起来)
继续跟进行值解析
getRowValue
java">private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 创建javaBean对应的实例,就是ResultMap上对应的javaType类型
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
// 如果结果无直接的类型处理器,则进行字段映射
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
// 自动映射默认不开启,官方也不推荐使用,忽略
boolean foundValues = this.useConstructorMappings;
if (shouldApplyAutomaticMappings(resultMap, false)) {
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
// 通过MetaObject,进行属性值反射设置
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
createResultObject方法,创建对应javaBean实例,如果用户指定了其类型处理器,那么会交由其处理,如果未指定则需要进行属性映射。
这里createResultObject的实现就不跟了,我们清楚只是创建一个空属性的实例即可。
看下属性映射,MetaObject之前反射包解析过,可以像操作map一样操作普通类。
applyPropertyMappings
java">private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
//获取所有映射的字段名(即resultMap中主动写了映射的字段)
final List<String> mappedColumnNames = rsw.getMappedColumnNames(resultMap, columnPrefix);
boolean foundValues = false;
//获得所有属性映射
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
//遍历属性映射,挨个字段映射
for (ResultMapping propertyMapping : propertyMappings) {
String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
if (propertyMapping.getNestedResultMapId() != null) {
// the user added a column attribute to a nested result map, ignore it
column = null;
}
if (propertyMapping.isCompositeResult()
|| (column != null && mappedColumnNames.contains(column.toUpperCase(Locale.ENGLISH)))
|| propertyMapping.getResultSet() != null) {
/*
* 属性值
* 根据字段名从ResultSet中获取值,由typeHandler进行转换
*/
Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);
// issue #541 make property optional
// 属性名
final String property = propertyMapping.getProperty();
if (property == null) {
continue;
} else if (value == DEFERRED) {
foundValues = true;
continue;
}
if (value != null) {
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() && !metaObject.getSetterType(property).isPrimitive())) {
// gcode issue #377, call setter on nulls (value is not 'found')
// 使用反射工具类,给属性赋值
metaObject.setValue(property, value);
}
}
}
return foundValues;
}
- 遍历ResultMapping。
- 属性值获取
- 反射设置
中间一些嵌套查询、延迟加载的可以忽略。
getPropertyMappingValue
java">private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
// 嵌套,忽略
if (propertyMapping.getNestedQueryId() != null) {
return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);
}
// 多数据集,忽略
else if (propertyMapping.getResultSet() != null) {
addPendingChildRelation(rs, metaResultObject, propertyMapping); // TODO is that OK?
return DEFERRED;
}
// 正常情况
else {
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);
// 由类型处理器进行值获取、转换
return typeHandler.getResult(rs, column);
}
}
到这里结果值的处理已经结束,和之前设想的流程一对,几乎是一致的。
只是在分支上增加了对嵌套查询、存储过程等进行了处理。
总结
在对结果值的处理时,其实大体流程不复杂,但是mybatis考虑的点比较多,做了一个通用处理,我们抓住核心,就会发现和我们想的一样简单。
That’s All
![[报告]codeforces 175d Plane of Tanks: Duel](http://bbs.saraba1st.com/2b/images/post/smile/face/145.gif)


![[C# 基础知识梳理系列]专题五:当点击按钮时触发Click事件背后发生的事情](http://pic002.cnblogs.com/p_w_picpaths/2012/383187/2012102817033830.png)